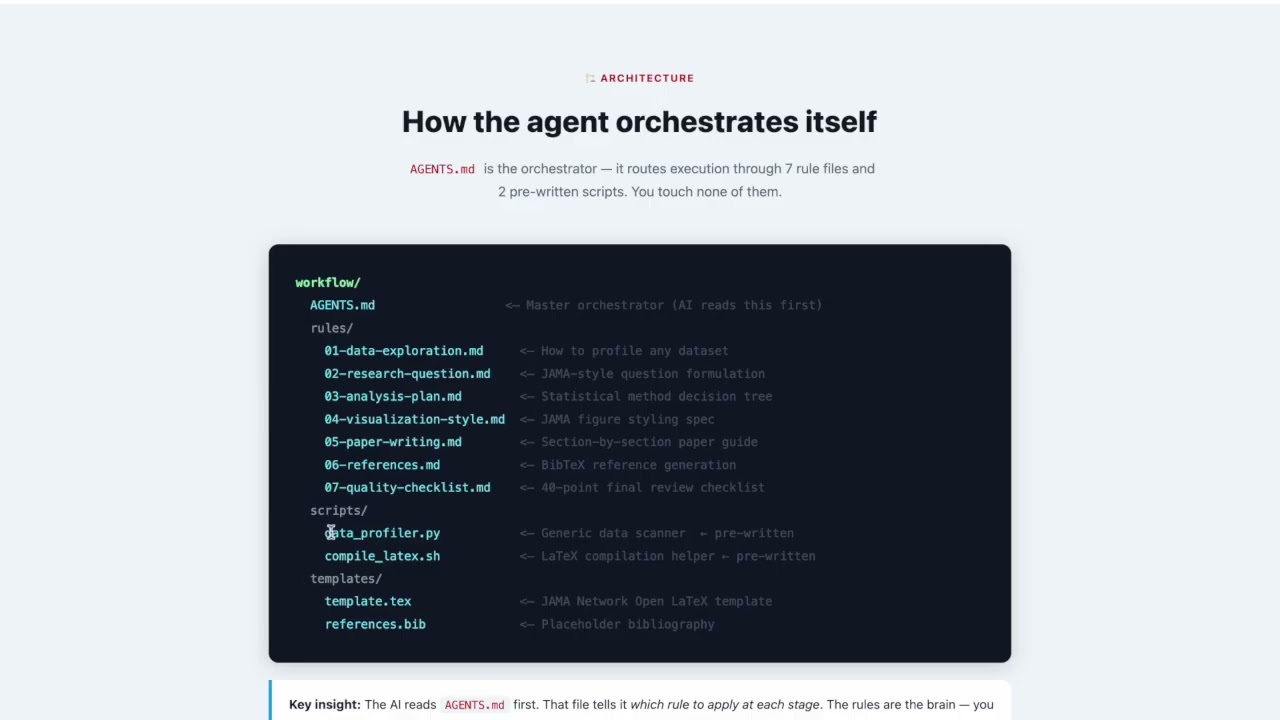
The 5-stage automated pipeline
Each stage runs sequentially and produces real, auditable output files you can inspect at any time.
The agent reads Data_Description.md, then runs data_profiler.py on every file — column names, data types, missing-value rates, date ranges, and cross-file merge keys — without you touching the data.
Based on the profile, the agent identifies exposure, outcome, population, and study design — then writes a formal JAMA-style objective a reviewer would accept.
The agent writes a complete analysis.py from scratch, executes it, and verifies all outputs. Four publication-quality figures are generated with JAMA styling.
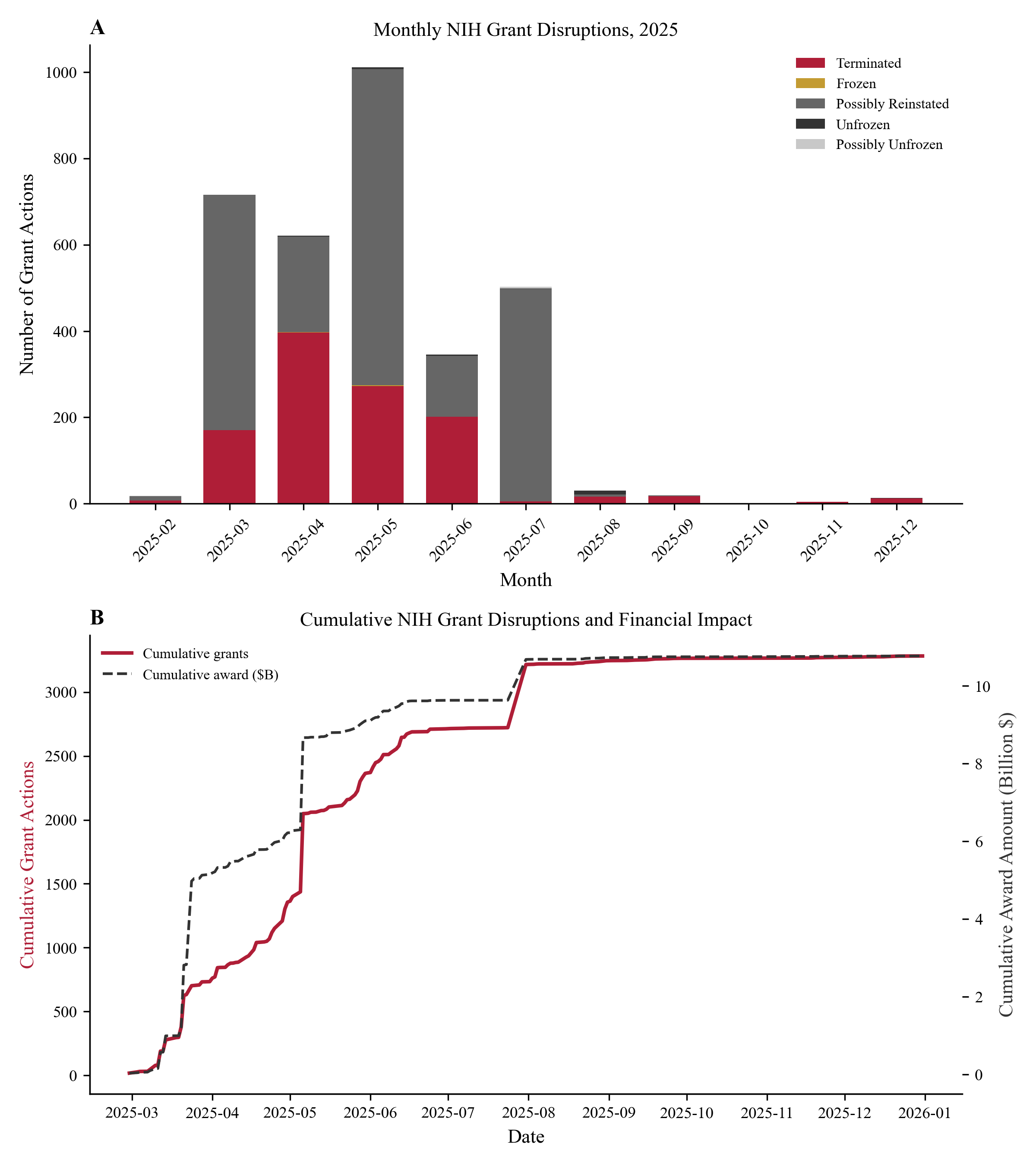
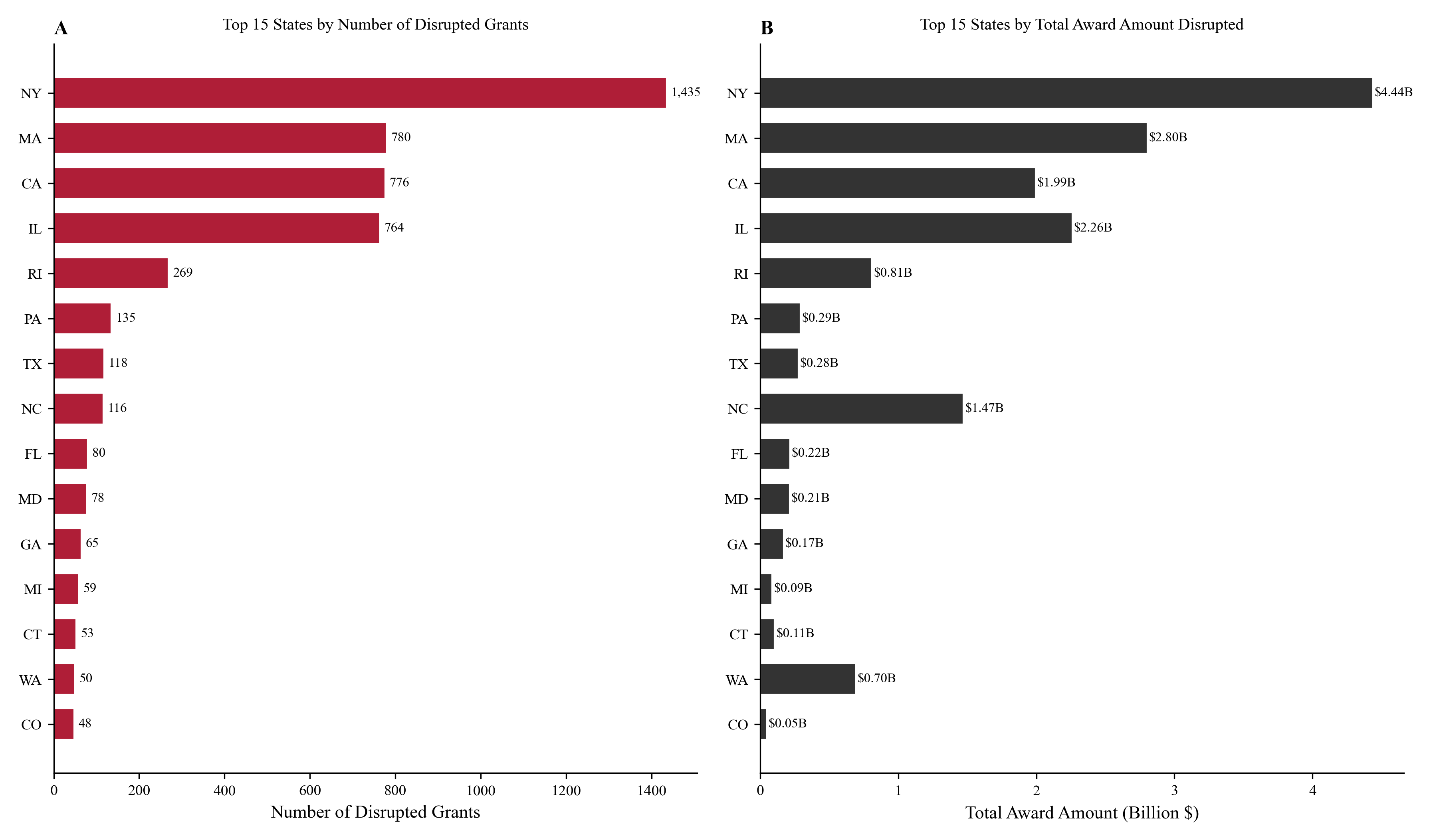
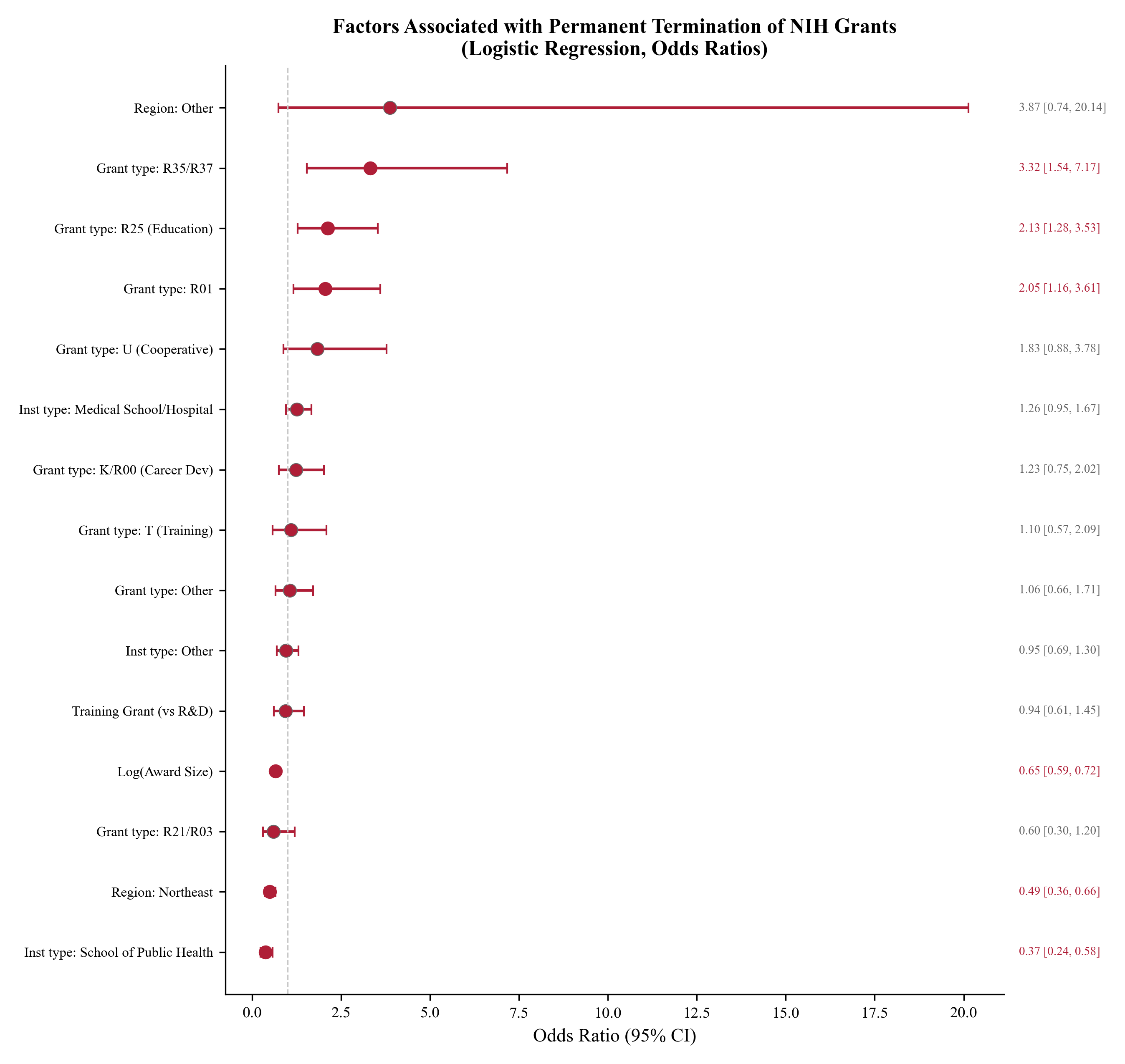
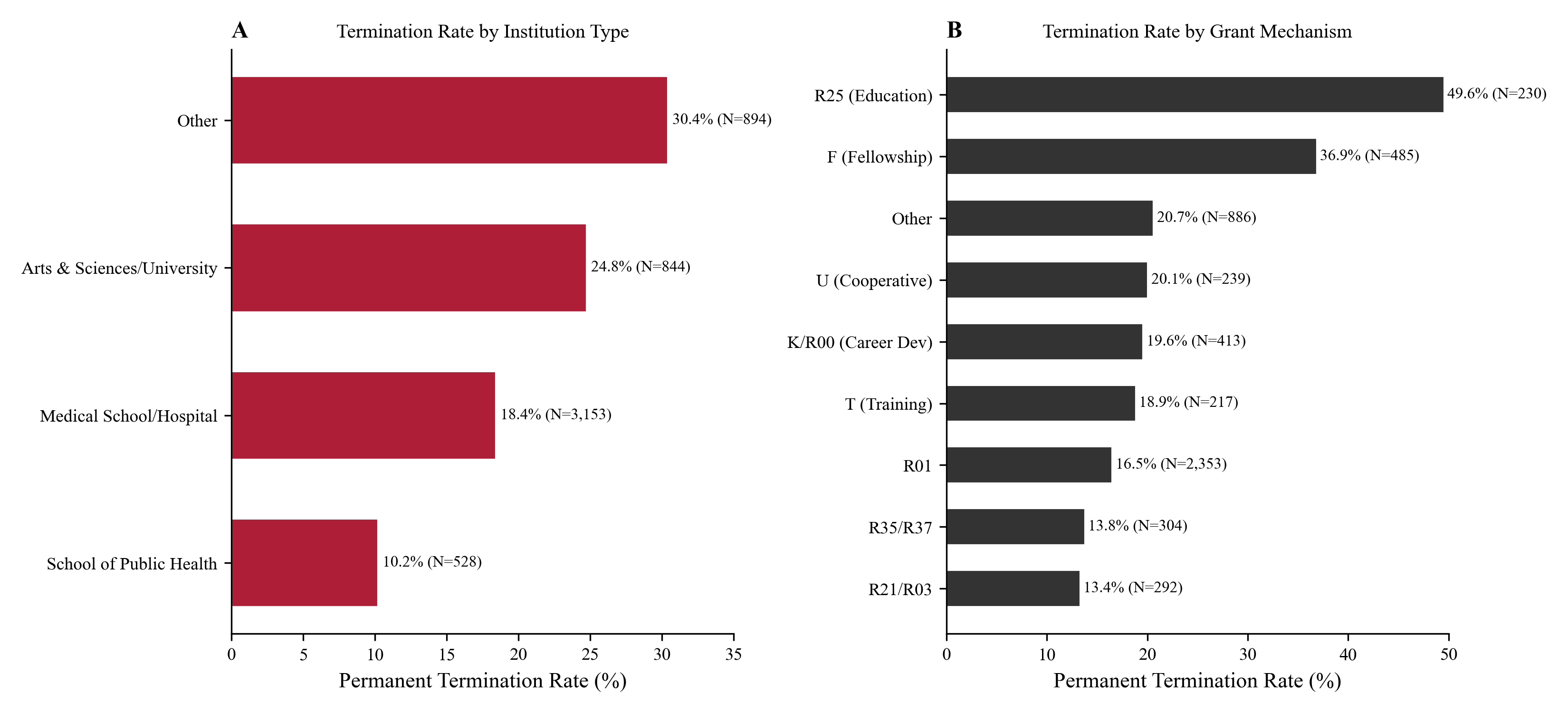
The agent fills every section of the JAMA LaTeX template with exact numbers from the CSVs, then searches online for real papers and builds a 31-entry BibTeX bibliography.
A 40-point checklist verifies every number before compilation. After passing, pdflatex runs three passes automatically — no manual intervention.